Today's AI assistants, such as ChatGPT, derive their knowledge primarily from text-based data, mostly sourced from the web and supplemented by printed materials like books.
While vast, this text serves as a limited proxy for true knowledge— reflecting human experiences and filtered through human perspectives.
The ultimate goal of modern AI is artificial general intelligence (AGI)— a system capable of reasoning like a human.
However, current AI is constrained by its reliance on textual data, which is an incomplete representation of the natural world.
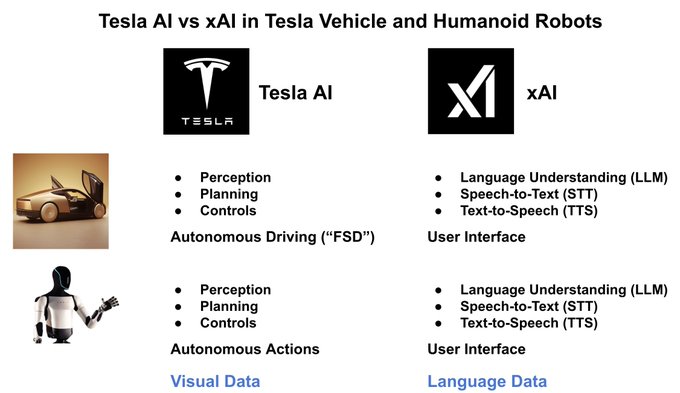
Tesla AI is a vision-based AI system. Its purpose is to control the actions of both the 4-wheeled robots (vehicles) and the 2-legged robots (Optimus). Specifically it trains AI models to manage the perception and planning for autonomy.
Moreover humans do not reason through text alone; reasoning requires experiential data from all our senses and interactions with both other humans and the environment.
Here, we will explore visual data, the most dominant sensory input for humans, and discuss how Tesla's forthcoming humanoid bot, Optimus, can leverage this data to build its knowledge base.
Visual information will support the bot's reasoning capabilities and serve as a critical data input modality for future AI systems.
xAI, on the other hand, builds language-based AI systems, essentially LLMs. The most notable example is the Grok AI assistant incorporated into X (this platform).
xAI will license its AI systems to Tesla for integration into both Tesla vehicles and Optimus robots.
The AI will function as a user interface, enabling natural voice interactions. For Tesla vehicles, particularly Robotaxis, users will interact via speech.
Similarly, Optimus robots will feature a voice-based human interface. Speech will be converted into LLM prompts using speech-to-text AI models, interpreted by the LLM model, and responses will be generated using text-to-speech AI models.
But xAI will do more.
AI language models are often referred to as large language models (LLMs) because they are trained on vast amounts of text data, allowing them to generate and understand human-like language. The "large" in LLMs refers to the scale of their architecture, typically involving billions or even trillions of parameters, which enables them to process and generate complex linguistic patterns with high accuracy.
AI language models like GPT-3 and GPT-4 are trained on textual data collected from diverse sources, encompassing a wide variety of human knowledge, perspectives, and contexts.
These sources include web pages gathered through large-scale web crawling, licensed and public domain books, encyclopedias like Wikipedia, research papers from open-access repositories, and online discussion platforms.
Additionally, datasets often include news articles and programming code from public repositories, capturing both formal and informal styles of communication. This wide-ranging approach ensures the models are capable of understanding and generating text across multiple domains, languages, and levels of complexity.
The scale of data used in training is staggering. For instance, GPT-3 was trained on approximately 300 billion tokens, roughly equivalent to 570GB of raw text data, while later models like GPT-4 likely utilize several trillion tokens, expanding the dataset to terabytes of information.
These datasets are carefully curated to maintain a balance between quality and diversity, removing duplicate or low-value content where possible.
This massive influx of high-volume data allows large language models to learn complex linguistic patterns and relationships, making them powerful tools for a wide array of natural language processing tasks.